LZW(Abraham Lempel、Jacob Ziv、Terry Welch)圧縮
データ列を可逆圧縮する符号化の中で、現在のデータ圧縮・画像圧縮等で広く用いられて居る圧縮で有る。此れは、或るデータ列に着目して、其れが以前に出現した事が有るかを調べ、既に出現した事が有れば、其のデータ列を示す符号に置き換える方法で有る。
LZW圧縮には、幾つかの種類が有り、1977年に発表された物をLZ77、其の翌年に発表された物をLZ78と呼んで区別して居るが、其の違いは符号化の方法丈で、処理の内容に付いては総て同じで有る。此処では、Byteデータの圧縮を念頭に、LZ78に付いて説明する。
| ※ |
LZ77では、前に出現したデータ列から最も長く一致した部分列を検索して、其の場所を指す事に依り圧縮を行う。
|
| ※ |
LZ78では、データ列を辞書に登録して置いて、辞書に有るデータは其の場所に置き換える事で圧縮を行う。
|
LZW圧縮は、GIF画像ファイルで常に使用されて居り、TIFFやPostScriptでは、オプションと仕て使用されて居る。
| ※ |
日本に於けるLZWに関する特許は、米国ユニシス社が出願、保有して居たが、2004年6月20日を以て失効して居る(日本ユニシス株式会社のサイトより)。
|
圧縮(Compress)
LZW圧縮では、最初に1バイトで表す事の出来る値0(00H)〜255(FFH)の256種類を辞書に登録して置く。更に、辞書を際限無く大きくする事が出来ない為、辞書が一定量を超えた時、辞書を初期化する為のコードを256(100H)に登録して置く。亦、此れは必ずしも必須では無いが、データの終端を示す為のコードを257(101H)に登録して置くのが一般的で有る。
下記に、圧縮前のデータ、圧縮後のデータ、及び、辞書データを示す。
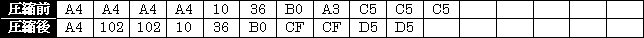

圧縮前と圧縮後のデータを比較すると、確かにデータの個数は減少して居るが、圧縮前のデータが、総て1バイト(8ビット)のデータで有るのに対して、圧縮後のデータは、102Hの様に、1バイトでは表せないデータ(9ビット)が含まれて居る。9ビットのデータ型と謂うのは無いので、此れを格納出来る2バイトのデータ型(Short)を圧縮後のデータに使用すれば、逆にデータ量が増えて了う。
此の問題の解消法は後述すると仕て、先ずは、LZW圧縮に於ける符号化(Encoding)の手順を、下記のデータを例と仕て、説明する。
| 元データ | A4 | A4 | A4 | A4 | 10 | 36 | B0 | A3 | C5 | C5 | C5 |
- 最初のデータA4Hを、変数Wに格納する(此の変数Wをプレフィックスと呼ぶ)。
W = "A4"
- 変数Wに格納されて居る値と同じ内容を持つ辞書番号を変数Nに格納する。
変数Wに格納されて居る値 "A4" は、辞書番号00A4Hに登録されて居る。
N = 164(= &HA4、0xA4)
- 次(2番目)のデータA4Hを、変数Kに格納する(此の変数Kをサフィックスと呼ぶ)。
K = "A4"
- 変数Wと変数Kを結合した値 "A4A4" が、辞書に登録されて居るか調査する。
登録されて居ないので、下記の処理を行う。
此の値 "A4A4" を、辞書に追加登録する。
"A4A4" と謂う値が、辞書番号0102Hに登録される。
圧縮データと仕て変数Nの値164を出力する(此の時の変数Nの値は、最長一致の辞書番号)。
変数Wに変数Kの値 "A4" を格納する(新たなプレフィックスの設定)。
W = K(= "A4")
- 変数Wに格納されて居る値と同じ内容を持つ辞書番号を変数Nに格納する。
変数Wに格納されて居る値 "A4" は、辞書番号00A4Hに登録されて居る。
N = 164(= &HA4、0xA4)
- 次(3番目)のデータA4Hを、変数Kに格納する
K = "A4"
- 変数Wと変数Kを結合した値 "A4A4" が、辞書に登録されて居るか調査する。
登録されて居るので、下記の処理を行う。
変数Wと変数Kを結合した値 "A4A4" と同じ内容を持つ辞書番号を変数Nに格納する。
即ち、"A4A4" と謂う値は、辞書番号0102Hに登録されて居るで、変数Nに102Hを格納。
N = 258(&H102、0x102)
変数Wと変数Kを結合した値 "A4A4" を変数Wに格納する。
W = W + K(= "A4A4")
- 次(4番目)のデータA4Hを、変数Kに格納する
K = "A4"
- 変数Wと変数Kを結合した値 "A4A4A4" が、辞書に登録されて居るか調査する。
登録されて居ないので、下記の処理を行う。
此の値 "A4A4A4" を、辞書に追加登録する。
"A4A4A4" と謂う値が、辞書番号0103Hに登録される。
圧縮データと仕て変数Nの値258を出力する(此の時の変数Nの値は、最長一致の辞書番号)。
変数Wに変数Kの値 "A4" を格納する(新たなプレフィックスの設定)。
W = K(= "A4")
- 変数Wに格納されて居る値と同じ内容を持つ辞書番号を変数Nに格納する。
変数Wに格納されて居る値 "A4" は、辞書番号00A4Hに登録されて居る。
N = 164(= &HA4、0xA4)
- 次(5番目)のデータ10Hを、変数Kに格納する
K = "10"
- 変数Wと変数Kを結合した値 "A410" が、辞書に登録されて居るか調査する。
登録されて居ないので、下記の処理を行う。
此の値 "A410" を、辞書に追加登録する。
"A410" と謂う値が、辞書番号0104Hに登録される。
圧縮データと仕て変数Nの値164を出力する(此の時の変数Nの値は、最長一致の辞書番号)。
変数Wに変数Kの値 "10" を格納する(新たなプレフィックスの設定)。
W = K(= "10")
- 変数Wに格納されて居る値と同じ内容を持つ辞書番号を変数Nに格納する。
変数Wに格納されて居る値 "10" は、辞書番号0010Hに登録されて居る。
N = 16(= &H10、0x10)
- 次(6番目)のデータ36Hを、変数Kに格納する
K = "36"
- 変数Wと変数Kを結合した値 "1036" が、辞書に登録されて居るか調査する。
登録されて居ないので、下記の処理を行う。
此の値 "1036" を、辞書に追加登録する。
"1036" と謂う値が、辞書番号0105Hに登録される。
圧縮データと仕て変数Nの値16を出力する(此の時の変数Nの値は、最長一致の辞書番号)。
変数Wに変数Kの値 "36" を格納する(新たなプレフィックスの設定)。
W = K(= "36")
- 変数Wに格納されて居る値と同じ内容を持つ辞書番号を変数Nに格納する。
変数Wに格納されて居る値 "36" は、辞書番号0036Hに登録されて居る。
N = 54(= &H36、0x36)
- 次(7番目)のデータB0Hを、変数Kに格納する
K = "B0"
- 変数Wと変数Kを結合した値 "36B0" が、辞書に登録されて居るか調査する。
登録されて居ないので、下記の処理を行う。
此の値 "36B0" を、辞書に追加登録する。
"36B0" と謂う値が、辞書番号0106Hに登録される。
圧縮データと仕て変数Nの値54を出力する(此の時の変数Nの値は、最長一致の辞書番号)。
変数Wに変数Kの値 "B0" を格納する(新たなプレフィックスの設定)。
W = K(= "B0")
- 変数Wに格納されて居る値と同じ内容を持つ辞書番号を変数Nに格納する。
変数Wに格納されて居る値 "B0" は、辞書番号00B0Hに登録されて居る。
N = 176(= &HB0、0xB0)
- 次(8番目)のデータA3Hを、変数Kに格納する
K = "A3"
- 変数Wと変数Kを結合した値 "B0A3" が、辞書に登録されて居るか調査する。
登録されて居ないので、下記の処理を行う。
此の値 "B0A3" を、辞書に追加登録する。
"B0A3" と謂う値が、辞書番号0107Hに登録される。
圧縮データと仕て変数Nの値176を出力する(此の時の変数Nの値は、最長一致の辞書番号)。
変数Wに変数Kの値 "A3" を格納する(新たなプレフィックスの設定)。
W = K(= "A3")
- 変数Wに格納されて居る値と同じ内容を持つ辞書番号を変数Nに格納する。
変数Wに格納されて居る値 "A3" は、辞書番号00A3Hに登録されて居る。
N = 163(= &HA3、0xA3)
- 次(9番目)のデータC5Hを、変数Kに格納する
K = "C5"
- 変数Wと変数Kを結合した値 "A3C5" が、辞書に登録されて居るか調査する。
登録されて居ないので、下記の処理を行う。
此の値 "A3C5" を、辞書に追加登録する。
"A3C5" と謂う値が、辞書番号0108Hに登録される。
圧縮データと仕て変数Nの値163を出力する(此の時の変数Nの値は、最長一致の辞書番号)。
変数Wに変数Kの値 "C5" を格納する(新たなプレフィックスの設定)。
W = K(= "C5")
- 変数Wに格納されて居る値と同じ内容を持つ辞書番号を変数Nに格納する。
変数Wに格納されて居る値 "C5" は、辞書番号00C5Hに登録されて居る。
N = 197(= &HC5、0xC5)
- 次(10番目)のデータC5Hを、変数Kに格納する
K = "C5"
- 変数Wと変数Kを結合した値 "C5C5" が、辞書に登録されて居るか調査する。
登録されて居ないので、下記の処理を行う。
此の値 "C5C5" を、辞書に追加登録する。
"C5C5" と謂う値が、辞書番号0109Hに登録される。
圧縮データと仕て変数Nの値197を出力する(此の時の変数Nの値は、最長一致の辞書番号)。
変数Wに変数Kの値 "C5" を格納する(新たなプレフィックスの設定)。
W = K(= "C5")
- 変数Wに格納されて居る値と同じ内容を持つ辞書番号を変数Nに格納する。
変数Wに格納されて居る値 "C5" は、辞書番号00C5Hに登録されて居る。
N = 197(= &HC5、0xC5)
- 次(11番目)のデータC5Hを、変数Kに格納する
K = "C5"
- 変数Wと変数Kを結合した値 "C5C5" が、辞書に登録されて居るか調査する。
登録されて居るので、下記の処理を行う。
変数Wと変数Kを結合した値 "C5C5" と同じ内容を持つ辞書番号を変数Nに格納する。
即ち、"C5C5" と謂う値は、辞書番号0109Hに登録されて居るで、変数Nに109Hを格納。
N = 265(&H109、0x109)
変数Wと変数Kを結合した値 "C5C5" を変数Wに格納する。
W = W + K(= "C5C5")
- 此れ以上データが無いので、最後のデータと仕て変数Nの値を出力する。
圧縮データと仕て変数Nの値265を出力する(此の時の変数Nの値は、最長一致の辞書番号)。
以上で元データA4、A4、A4、A4、10、36、B0、A3、C5、C5、C5をLZW圧縮する全工程を記したが、以上の手順を纏めると、下記の様に成る。
- 最初のデータを、変数Wに格納する(此の変数Wをプレフィックスと呼ぶ)。猶、各データの区切り位置が解り易い様に、各データを2文字の16進数で文字列に変換して格納して居る。
- 元データ用指標Iを1に設定する(最初のデータは処理済で有る為)。
- 変数Wに格納されて居る値と同じ内容を持つ辞書番号を変数Nに格納する。
- 指標Iの指す位置のデータを、変数Kに格納する(此の変数Kをサフィックスと呼ぶ)。此れも変数Wと同様、2文字の16進数で文字列に変換して格納して居る。
- 指標Iを1進める(インクリメント)。
- 変数Wと変数Kを結合した値が、辞書に登録されて居るか調査する。
- 辞書に登録されて居る場合は、
変数Wと変数Kを結合した値と同じ内容を持つ辞書番号を変数Nに格納する。
変数Wと変数Kを結合した値を変数Wに格納する。
- 辞書に登録されて居ない場合は、
変数Wと変数Kを結合した値を辞書に登録する。
圧縮データと仕て変数Nの値を出力する。
変数Wに変数Kの値を格納する(新たなプレフィックスの設定)。
- 未だ元データが有る場合は、3に戻り、処理を繰り返す。
- 最後に必ずデータが残るので、変数Nに格納されて居る値を、圧縮データと仕て出力する。
下記に、LZW圧縮を使用してByteデータを圧縮するコード例を示す。猶、Byte配列Srcに元データが格納されて居る物とする。亦、圧縮結果は、Short配列Lzwに格納される。
| Visual Basic 2005/2008/2010 |
' 辞書の初期化
Dic = New ArrayList()
For C As Integer = 0 To 255
Dic.Add(C.ToString("X").PadLeft(2, "0"c))
Next
Dic.Add("CLEAR") ' クリアコード
Dic.Add("END") ' 終了コード
' 圧縮
Dim I As Integer = 0
Dim N As Integer = 0
Dim W As String = "" ' プレフィックス
Dim K As String = "" ' サフィックス
Dat = New ArrayList()
W = Src(I).ToString("X").PadLeft(2, "0"c) : I += 1
Do Until I >= Src.Length
N = Dic.IndexOf(W)
K = Src(I).ToString("X").PadLeft(2, "0"c) : I += 1
If Dic.Contains(W & K) Then
N = Dic.IndexOf(W & K)
W = W & K
Else
Dic.Add(W & K)
Dat.Add(N)
W = K
End If
Loop
Dat.Add(N)
' 圧縮データの作成
ReDim Lzw(Dat.Count - 1)
For I = 0 To (Dat.Count - 1)
Lzw(I) = Short.Parse(Dat.Item(I))
Next
|
| Visual C# 2005/2008/2010 |
// 辞書の初期化
dic = new ArrayList();
for (int c = 0; c < 256; c++)
{
dic.Add(c.ToString("X").PadLeft(2, '0'));
}
dic.Add("CLEAR"); // クリアコード
dic.Add("END"); // 終了コード
// 圧縮
int i = 0;
int n = 0;
string w = ""; // プレフィックス
string k = ""; // サフィックス
dat = new ArrayList();
w = src[i++].ToString("X").PadLeft(2, '0');
while (i < src.Length)
{
n = dic.IndexOf(w);
k = src[i++].ToString("X").PadLeft(2, '0');
if (dic.Contains(w + k))
{
n = dic.IndexOf(w + k);
w = w + k;
}
else
{
dic.Add(w + k);
dat.Add(n);
w = k;
}
}
dat.Add(n);
// 圧縮データの作成
lzw = new ushort[dat.Count];
for (i = 0; i < dat.Count; i++)
{
lzw[i] = (ushort)System.Convert.ToInt16(dat[i]);
}
|
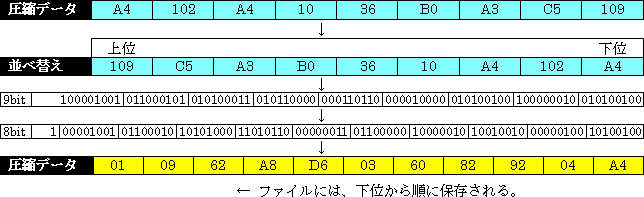
前述の様に、圧縮後のデータに2バイトのデータ型(Short又はUShort)を使用して居れば、期待する様な圧縮効果は得られない(上記の例では、逆に、データ量が増加して居る)。其処で、圧縮したデータを、9ビットデータと仕て、下位から順に並べ、其れを8ビットデータと仕て区切り直したデータを、最終的な圧縮データを仕て居る。
| ※ |
上記の例では、元データが11バイト、圧縮データが11バイトで有り、実際には、何も圧縮されて居ない。此れは、データの冗長性(連続性)に依る物で有る。
|
下記に、LZW圧縮を使用してByteデータを圧縮するコード例を示す。猶、Byte配列Srcに元データが格納されて居る物とする。亦、圧縮結果は、Byte配列Lzwに格納される。
| Visual Basic 2005/2008/2010 |
' 辞書の初期化
Dic = New ArrayList()
For C As Integer = 0 To 255
Dic.Add(C.ToString("X").PadLeft(2, "0"c))
Next
Dic.Add("CLEAR") ' クリアコード
Dic.Add("END") ' 終了コード
' 圧縮
Dim W As String = "" ' プレフィックス
Dim K As String = "" ' サフィックス
Dat = New ArrayList()
I = 0 : N = 0
W = Src(I).ToString("X").PadLeft(2, "0"c) : I += 1
Do Until I >= Src.Length
N = Dic.IndexOf(W)
K = Src(I).ToString("X").PadLeft(2, "0"c) : I += 1
If Dic.Contains(W & K) Then
N = Dic.IndexOf(W & K)
W = W & K
Else
Dic.Add(W & K)
Dat.Add(N)
W = K
End If
Loop
Dat.Add(N)
' 暫定圧縮データの作成(UShort化)
Dim Tmp(Dat.Count - 1) As UShort
For I = 0 To (Dat.Count - 1)
Tmp(I) = Short.Parse(Dat.Item(I))
Next
' 9ビット→8ビット
Dim Num As ArrayList = New ArrayList()
S = ""
For I = 0 To (Tmp.Length - 1)
S = GetBinStr(Tmp(I), 9) & S
Do Until S.Length < 8
N = S.Length - 8
Num.Add(System.Convert.ToByte(S.Substring(N), 2))
S = S.Substring(0, N)
Loop
Next
If S.Length > 0 Then
Num.Add(System.Convert.ToByte(S, 2))
End If
' 圧縮データの作成
ReDim Lzw(Num.Count - 1)
For I = 0 To (Num.Count - 1)
Lzw(I) = Byte.Parse(Num.Item(I))
Next
|
| Visual C# 2005/2008/2010 |
// 辞書の初期化
dic = new ArrayList();
for (int c = 0; c < 256; c++)
{
dic.Add(c.ToString("X").PadLeft(2, '0'));
}
dic.Add("CLEAR"); // クリアコード
dic.Add("END"); // 終了コード
// 圧縮
int i = 0;
int n = 0;
string w = ""; // プレフィックス
string k = ""; // サフィックス
dat = new ArrayList();
w = src[i++].ToString("X").PadLeft(2, '0');
while (i < src.Length)
{
n = dic.IndexOf(w);
k = src[i++].ToString("X").PadLeft(2, '0');
if (dic.Contains(w + k))
{
n = dic.IndexOf(w + k);
w = w + k;
}
else
{
dic.Add(w + k);
dat.Add(n);
w = k;
}
}
dat.Add(n);
// 圧縮データの作成
lzw = new ushort[dat.Count];
for (i = 0; i < dat.Count; i++)
{
lzw[i] = (ushort)System.Convert.ToInt16(dat[i]);
}
|
展開(Expand)
次に、LZW圧縮に於ける復号化(Decoding)の手順を、下記のデータを例と仕て、説明する。
| 圧縮データ | A4 | 102 | A4 | 10 | 36 | B0 | A3 | C5 | 109 |
猶、展開に先立ち、下記の基本辞書が用意されて居る必要が有る。
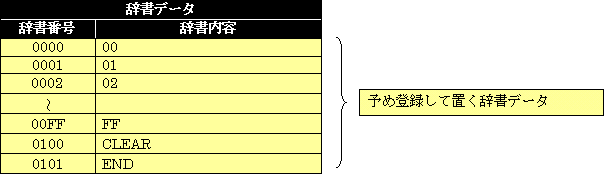
亦、上記のデータを、9ビットデータと仕て、下位から順に並べ、其れを8ビットデータと仕て区切り直したデータの場合は、予め、上記のShort配列に戻して置く必要が有る。
- 最初のデータA4Hを、変数Wに格納する(此の変数Wをプレフィックスと呼ぶ)。
W = "A4"
- 次(2番目)のデータ102Hが、辞書の登録数以上で有るか調べる。
現在の辞書の登録数は102H個なので、下記の登録数以上の処理を行う。
変数Wと変数Wの最初のデータを結合した値 "A4A4" を、辞書に追加登録する。
"A4A4" と謂う値が、辞書番号0102Hに登録される。
此の値102Hが指す辞書内容を、変数Kに格納する。
K = "A4A4"
変数Wに含まれるデータを、夫々展開データと仕て出力する。
変数Wの値は "A4" なので、A4Hが出力される。
変数Kの値 "A4A4" を変数Wに格納する。
W = K(= "A4A4")
- 次(3番目)のデータA4Hが、辞書の登録数以上で有るか調べる。
現在の辞書の登録数は103H個なので、下記の登録数未満の処理を行う。
此の値A4Hが指す辞書内容を、変数Kに格納する。
K = "A4"
変数Wと変数Kの最初のデータを結合した値 "A4A4A4" を、辞書に追加登録する。
"A4A4A4" と謂う値が、辞書番号0103Hに登録される。
変数Wに含まれるデータを、夫々展開データと仕て出力する。
変数Wの値は "A4A4" なので、A4H、A4Hが出力される。
変数Kの値 "A4" を変数Wに格納する。
W = K(= "A4")
- 次(4番目)のデータ10Hが、辞書の登録数以上で有るか調べる。
現在の辞書の登録数は104H個なので、下記の登録数未満の処理を行う。
此の値10Hが指す辞書内容を、変数Kに格納する。
K = "10"
変数Wと変数Kの最初のデータを結合した値 "A410" を、辞書に追加登録する。
"A410" と謂う値が、辞書番号0104Hに登録される。
変数Wに含まれるデータを、夫々展開データと仕て出力する。
変数Wの値は "A4" なので、A4Hが出力される。
変数Kの値 "10" を変数Wに格納する。
W = K(= "10")
- 次(5番目)のデータ36Hが、辞書の登録数以上で有るか調べる。
現在の辞書の登録数は105H個なので、下記の登録数未満の処理を行う。
此の値36Hが指す辞書内容を、変数Kに格納する。
K = "36"
変数Wと変数Kの最初のデータを結合した値 "1036" を、辞書に追加登録する。
"1036" と謂う値が、辞書番号0105Hに登録される。
変数Wに含まれるデータを、夫々展開データと仕て出力する。
変数Wの値は "10" なので、10Hが出力される。
変数Kの値 "36" を変数Wに格納する。
W = K(= "36")
- 次(6番目)のデータB0Hが、辞書の登録数以上で有るか調べる。
現在の辞書の登録数は106H個なので、下記の登録数未満の処理を行う。
此の値B0Hが指す辞書内容を、変数Kに格納する。
K = "B0"
変数Wと変数Kの最初のデータを結合した値 "36B0" を、辞書に追加登録する。
"36B0" と謂う値が、辞書番号0106Hに登録される。
変数Wに含まれるデータを、夫々展開データと仕て出力する。
変数Wの値は "36" なので、36Hが出力される。
変数Kの値 "B0" を変数Wに格納する。
W = K(= "B0")
- 次(7番目)のデータA3Hが、辞書の登録数以上で有るか調べる。
現在の辞書の登録数は107H個なので、下記の登録数未満の処理を行う。
此の値A3Hが指す辞書内容を、変数Kに格納する。
K = "A3"
変数Wと変数Kの最初のデータを結合した値 "B0A3" を、辞書に追加登録する。
"B0A3" と謂う値が、辞書番号0107Hに登録される。
変数Wに含まれるデータを、夫々展開データと仕て出力する。
変数Wの値は "B0" なので、B0Hが出力される。
変数Kの値 "A3" を変数Wに格納する。
W = K(= "A3")
- 次(8番目)のデータC5Hが、辞書の登録数以上で有るか調べる。
現在の辞書の登録数は108H個なので、下記の登録数未満の処理を行う。
此の値C5Hが指す辞書内容を、変数Kに格納する。
K = "C5"
変数Wと変数Kの最初のデータを結合した値 "A3C5" を、辞書に追加登録する。
"A3C5" と謂う値が、辞書番号0108Hに登録される。
変数Wに含まれるデータを、夫々展開データと仕て出力する。
変数Wの値は "A3" なので、A3Hが出力される。
変数Kの値 "C5" を変数Wに格納する。
W = K(= "C5")
- 次(9番目)のデータ109Hが、辞書の登録数以上で有るか調べる。
現在の辞書の登録数は109H個なので、下記の登録数以上の処理を行う。
変数Wと変数Wの最初のデータを結合した値 "C5C5" を、辞書に追加登録する。
"C5C5" と謂う値が、辞書番号0109Hに登録される。
此の値109Hが指す辞書内容を、変数Kに格納する。
K = "C5C5"
変数Wに含まれるデータを、夫々展開データと仕て出力する。
変数Wの値は "C5" なので、C5Hが出力される。
変数Kの値 "C5C5" を変数Wに格納する。
W = K(= "C5C5")
- 此れ以上データが無いので、最後のデータと仕て変数Wの値を、夫々展開データと仕て出力する。
変数Wの値は "C5C5" なので、C5H、C5Hが出力される。
以上で圧縮データA4、102、A4、10、36、B0、A3、C5、109をLZW展開する全工程を記したが、以上の手順を纏めると、下記の様に成る。
- 最初のデータを、変数Wに格納する(此の変数Wをプレフィックスと呼ぶ)。猶、各データの区切り位置が解り易い様に、各データを2文字の16進数で文字列に変換して格納して居る。
- 圧縮データ用指標Iを1に設定する(最初のデータは処理済で有る為)。
- 指標Iが指す位置のデータが、辞書の登録数以上で有るか調べる。
- 登録数以上の場合は、
変数Wと変数Wの最初のデータを結合した値を、辞書に追加登録する。
指標Iが指す位置の辞書内容を、変数Kに格納する(此の変数Kをサフィックスと呼ぶ)。
指標Iの値を1進める(インクリメント)。
変数Wに含まれるデータを、夫々展開データと仕て出力する。
変数Kの値を変数Wに格納する(新たなプレフィックスの設定)。
- 登録数未満の場合は、
指標Iが指す位置の辞書内容を、変数Kに格納する。
指標Iの値を1進める(インクリメント)。
変数Wと変数Kの最初のデータを結合した値を、辞書に追加登録する。
変数Wに含まれるデータを、夫々展開データと仕て出力する。
変数Kの値を変数Wに格納する(新たなプレフィックスの設定)。
- 未だ元データが有る場合は、3に戻り、処理を繰り返す。
- 最後に必ずデータが残るので、変数Wに格納されて居る値を、夫々展開データと仕て出力する。
下記に、前項で圧縮したByteデータを展開するコード例を示す。猶、Short配列Lzwに圧縮データが格納されて居る物とする。亦、展開結果は、Byte配列Srcに格納される。
| Visual Basic 2005/2008/2010 |
' 辞書の初期化
Dic = New ArrayList()
For C As Integer = 0 To 255
Dic.Add(C.ToString("X").PadLeft(2, "0"c))
Next
Dic.Add("CLEAR") ' クリアコード
Dic.Add("END") ' 終了コード
' 解凍
Dim I As Integer = 0
Dim N As Integer = 0
Dim W As String = "" ' プレフィックス
Dim K As String = "" ' サフィックス
Dat = New ArrayList()
W = Dic.Item(Lzw(I)) : I += 1
Do Until I >= Lzw.Length
If Lzw(I) >= Dic.Count Then
Dic.Add(W & W.Substring(0, 2))
K = Dic.Item(Lzw(I)) : I += 1
For J As Integer = 0 To (W.Length - 1) Step 2
Dat.Add(W.Substring(J, 2))
Next
W = K
Else
K = Dic.Item(Lzw(I)) : I += 1
Dic.Add(W & K.Substring(0, 2))
For J As Integer = 0 To (W.Length - 1) Step 2
Dat.Add(W.Substring(J, 2))
Next
W = K
End If
Loop
For J As Integer = 0 To (W.Length - 1) Step 2
Dat.Add(W.Substring(J, 2))
Next
' 元データの作成
ReDim Src(Dat.Count - 1)
For I = 0 To (Dat.Count - 1)
Src(I) = Byte.Parse(Dat.Item(I), Globalization.NumberStyles.AllowHexSpecifier)
Next
|
| Visual C# 2005/2008/2010 |
// 辞書の初期化
dic = new ArrayList();
for (int c = 0; c < 256; c++) dic.Add(c.ToString("X").PadLeft(2, '0'));
dic.Add("CLEAR"); // クリアコード
dic.Add("END"); // 終了コード
// 解凍
int i = 0;
int n = 0;
string w = ""; // プレフィックス
string k = ""; // サフィックス
dat = new ArrayList();
w = dic[lzw[i++]].ToString();
while (i < lzw.Length)
{
tssProgress.Value = i;
if (lzw[i] >= dic.Count)
{
dic.Add(w + w.Substring(0, 2));
k = dic[lzw[i++]].ToString();
for (int j = 0; j < w.Length; j += 2) dat.Add(w.Substring(j, 2));
w = k;
}
else
{
k = dic[lzw[i++]].ToString();
dic.Add(w + k.Substring(0, 2));
for (int j = 0; j < w.Length; j += 2) dat.Add(w.Substring(j, 2));
w = k;
}
}
for (int j = 0; j < w.Length; j += 2) dat.Add(w.Substring(j, 2));
// 元データの作成
src = new byte[dat.Count];
for (i = 0; i < dat.Count; i++) src[i] = System.Convert.ToByte(dat[i].ToString(), 16);
|
下記に、前項で圧縮したByteデータを展開するコード例を示す。猶、Byte配列Lzwに圧縮データが格納されて居る物とする。亦、展開結果は、Byte配列Srcに格納される。
| Visual Basic 2005/2008/2010 |
' 8ビット→9ビット
Dim Num As ArrayList = New ArrayList()
S = ""
For I = 0 To (Lzw.Length - 1)
S = GetBinStr(System.Convert.ToUInt16(Lzw(I)), 8) & S
Do Until S.Length < 9
N = S.Length - 9
Num.Add(System.Convert.ToUInt16(S.Substring(N), 2))
S = S.Substring(0, N)
Loop
Next
If S.Length > 0 Then
N = System.Convert.ToByte(S, 2)
If Not N = 0 Then
Num.Add(System.Convert.ToByte(S, 2))
End If
End If
' 暫定圧縮データの作成(UShort化)
Dim Tmp(Num.Count - 1) As UShort
For I = 0 To (Num.Count - 1)
Tmp(I) = Short.Parse(Num.Item(I))
Next
' 辞書の初期化
Dic = New ArrayList()
For C As Integer = 0 To 255
Dic.Add(C.ToString("X").PadLeft(2, "0"c))
Next
Dic.Add("CLEAR") ' クリアコード
Dic.Add("END") ' 終了コード
' 解凍
Dim W As String = "" ' プレフィックス
Dim K As String = "" ' サフィックス
Dat = New ArrayList()
I = 0 : N = 0
W = Dic.Item(Tmp(I)) : I += 1
Do Until I >= Tmp.Length
tssProgress.Value = I
If Tmp(I) >= Dic.Count Then
Dic.Add(W & W.Substring(0, 2))
K = Dic.Item(Tmp(I)) : I += 1
For J As Integer = 0 To (W.Length - 1) Step 2
Dat.Add(W.Substring(J, 2))
Next
W = K
Else
K = Dic.Item(Tmp(I)) : I += 1
Dic.Add(W & K.Substring(0, 2))
For J As Integer = 0 To (W.Length - 1) Step 2
Dat.Add(W.Substring(J, 2))
Next
W = K
End If
Loop
For J As Integer = 0 To (W.Length - 1) Step 2
Dat.Add(W.Substring(J, 2))
Next
' 元データの作成
ReDim Src(Dat.Count - 1)
For I = 0 To (Dat.Count - 1)
Src(I) = Byte.Parse(Dat.Item(I), Globalization.NumberStyles.AllowHexSpecifier)
Next
|
| Visual C# 2005/2008/2010 |
// 辞書の初期化
dic = new ArrayList();
for (int c = 0; c < 256; c++) dic.Add(c.ToString("X").PadLeft(2, '0'));
dic.Add("CLEAR"); // クリアコード
dic.Add("END"); // 終了コード
// 解凍
int i = 0;
int n = 0;
string w = ""; // プレフィックス
string k = ""; // サフィックス
// 解凍
dat = new ArrayList();
w = dic[lzw[i++]].ToString();
while (i < lzw.Length)
{
if (lzw[i] >= dic.Count)
{
dic.Add(w + w.Substring(0, 2));
k = dic[lzw[i++]].ToString();
for (int j = 0; j < w.Length; j += 2) dat.Add(w.Substring(j, 2));
w = k;
}
else
{
k = dic[lzw[i++]].ToString();
dic.Add(w + k.Substring(0, 2));
for (int j = 0; j < w.Length; j += 2) dat.Add(w.Substring(j, 2));
w = k;
}
}
for (int j = 0; j < w.Length; j += 2) dat.Add(w.Substring(j, 2));
// 元データの作成
src = new byte[dat.Count];
for (i = 0; i < dat.Count; i++) src[i] = System.Convert.ToByte(dat[i].ToString(), 16);
|
ダウンロード
GIFファイルの圧縮
GIFファイルでは、常に、此の圧縮方法が用いられて居る。GIFファイルでは、辞書番号を表す値を、必ずしも9ビット固定とはせず、必要に応じて12ビット迄拡張して居る(此の為、画像ブロックにはLZW最小ビット長が有る)。辞書の最大項目数は、9ビットの場合512、12ビットの場合4096で有るが、此れを超えた場合、クリアコード(前述の辞書例では100H)を出力して、辞書の初期化を行う。
